

Nobody really knows which technologies will be the most widely used in the future. What we do know is that machine learning and AI will be essential building blocks. I have put together this machine learning algorithms overview post to demystify the topic, since most of the currently build on machine learning and AI.

Statistics
I will present deep learning modes very high level, however it is not the main focus. It is important to realize that there are other methods available as well. Maybe they are not that hyped and maybe they were part of statistic books before many of us were born.
via MEME
AWS Machine Learning Specialty
This post is also part of a series about the AWS Machine Learning Speciality (MLS-C01) exam. I have structured the content into eight separate posts. These posts can be consumed as a stand-alone material. If you are not preparing for the MLS-C01 exam you may still find the topics interesting:
- Part 1: The AWS Certified Machine Learning Consultant
- Part 2: The AWS Data Engineering Consultant
- Part 3: Top 7 Explorative Data Analysis Methods
- Part 4: Machine Learning Algorithms Overview
This post covers one of the domains in the MLS-C01 exam. Domain 3. Modeling:
- 3.1 Frame business problems as machine learning problems.
- 3.2 Select the appropriate model(s) for a given machine learning problem.
- 3.3 Train machine learning models.
- 3.4 Perform hyperparameter optimization.
- 3.5 Evaluate machine learning models.
Supervised Machine Learning Algorithms
https://scikit-learn.org/stable/supervised_learning.html
Regression
The aim of regression models is to a predict continuous value based on the input variables. E.g., house price based on the house’s location, size, year build, etc…
Most common regression algorithms:
- Linear regression: learns linear relationship between input and target variable.
- Polynomial regression: is able to learn non-linear relationships. Typical implementation is to pre-calculate polynomial variables, after which linear models can be applied.
- Decision Tree: learns a hierarchical threshold structure, like a deep IF-ELSE statement tree.
- Support Vector: tries to find a hyperplane which minimizes the prediction error (distance between sample and plane).
- KNN – K-nearest neighbours: for prediction looks up k most similar known samples and uses the e.g., the average target value as prediction.
Classification
The aim of classification models is to predict discrete values. If the target value has two possible values the problem is called binary classification. We refer to the values as negative (not spam, not anomaly) and positive cases.
When the target variable has multiple values the problem is called multiclass classification. It is possible to transform multiclass problem to binary:
- one-vs-one: all pairs evaluated with n * (n-1) / 2 binary classifiers
- one-vs-rest: one class picked at one time and is evaluated using binary classifiers, repeated n times (or n-1 – last class can be inferred from the other results).
Most common classification algorithms:
- Logistic regression: binary classification method, where a logistic function is as a decision function.
- Decision Tree: learns a hierarchical threshold structure, like a deep IF-ELSE statement tree.
- Support Vector: tries to find a hyperplane maximizes the gap between the different classes.
- KNN – K-nearest neighbours: for prediction looks up k most similar known samples and uses the majority target value as prediction.
Tip: To get optimal k plot “total within-cluster sum of square measures” for each k. Choose k where the value is not decreasing anymore (elbow method).
Ensemble
Ensemble methods are combination of multiple estimators, two main type can be distinguished:
- Averaging / bagging: train models on subset of the data and average the prediction. Random Forest: collection of decision trees.
- Boosting: sequentially train models and adjust weights assigned to each train sample to improve the target metric (e.g.: accuracy). E.g., AdaBoost, GradientBoost
Neural Network
- Feedforward neural network; single or Multi-Layer Perceptron (MLP): this is the „classic“ version where layers of multiple neurons are trained to solve regression and classification tasks. Think of the neuron as a numerical weight. This value multiplied by the input activates if a certain threshold is reached defined by an activation function.
- Convolutional Neural Network (CNN): typically used for image processing. Its main feature is to find patterns location independent. In real life you should start with a pre-trained network and only retrain the last fully connected layer(s), this approach is called transfer learning.
- Recurrent Neural Network (RNN): typically used for time series analysis. Its main feature is to „remember“ previous inputs providing historical context to the current input. It is used for example: IoT sensor data, stock market data or for variable length input like text translation. There are two main unit types to provide the „memory“ functionality:
- LSTM – Long Short Term Memory
- GRU – Gated recurrent unit
Activation Functions for Neural Networks
Activation functions calculate the actual output of the neuron and the final result of the net as well.
- Sigmoid, log, tanh: problem is the small gradient on the “edges” called vanishing gradient, because of numerically small values and slower learning. Solution: https://en.wikipedia.org/wiki/Vanishing_gradient_problem
- Multi-level hierarchy: pre-train layers through unsupervised learning
- For RNN: LSTM
- ReLU: gradient is “stable”
- Residual networks: for layer(s) K pass not only the output of K-1, but the input (X) as well
- https://chatbotslife.com/resnets-highwaynets-and-densenets-oh-my-9bb15918ee32
- ReLU: 0 for negative input and f(x) = x for positive
Unsupervised Machine Learning Algorithms
https://scikit-learn.org/stable/unsupervised_learning.html
As opposed to supervised algorithms for unsupervised no target attribute is available. Most widely used algorithms in this group are:
- Clustering / segmentation: similar to classification, only no target attribute is set, e.g.: K-means.
- Principal Component Analysis (PCA): dimension reduction by creating a specified number of features (n) out of the original data applying higher weights on fields with higher variance. When n is in [1, 2, 3] the data can be plotted for visual analysis.
- Outlier detection: identifies input samples which are out-of-the-ordinary.
- Latent Dirichlet allocation (LDA): topic modeling: separates documents by topics, the actual topic (name) is not inferred by the model.
Data set preparation
- Data should be shuffled in the first step.
- Training data and validation/test data should be separated.
- Stratified K fold: proportional number of samples are kept from each target class
- Two data sets approach:
- Train (~70%) and test data are separated. All training and hyperparameter tuning is done on the training data. Test data is only used for the final model evaluation.
- Three data sets approach:
- Train (70%), validation (15%) and test (15%) data are separated. Training is done on the training data, hyperparameter tuning is done on using the validation data. Test data is only used for the final model evaluation.
Algorithm Fine Tuning – Hyperparameter Optimization
Model fine tuning happens after initial data analysis was finished and one or more potential algorithms were selected to evaluate them against the target variable.
Tuning is an iterative process of adjusting hyperparameters and looking at the model’s changed performance. Main part of one iteration is to train the model and to record the performance KPIs. There are two types of KPIs: accuracy like (goal is to maximize) and error like (goal is to minimize).
It is crucial to recognize under- or overfitting for efficient model and parameter selection. Training and validation errors are visualized in the following image.
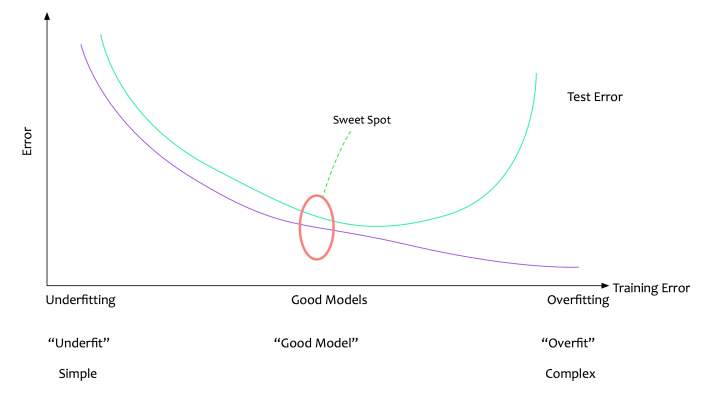
Hyperparameter Optimization
| Parameters | Underfitting | Overfitting |
|---|---|---|
| Input features | Add | Remove |
| Early stopping | Stop early | |
| Regularization | Apply L2 regularization – alpha = 0 – weights are small, but not zero – no feature selection – dense output | Apply L1 regularization – alpha = 1 – weights can go to zero – feature selection – sparse output |
| Regularization term | Increase reg. term (lambda) | Decrease reg. term (lambda) |
| Neural Network – layers | Add / increase | Reduce / decrease |
| Neural Network – dropout | Reduce / decrease | Add / increase |
Batch size: number of samples for one training iteration. If it’s too small it could be stuck in local minima. If it’s too large it could converge to a suboptimal solution.
Learning rate: “speed” of convergence. If it’s too small learning takes a long time. If it’s too big, it could overshoot the solution and oscillate.
Algorithm evaluation
Confusion matrix is the most basic tool to record an algorithm’s performance. The following table shows the structure and the naming convention.
| Actual Positive | Actual Negative | |
| Predicted – Positive | TP – True Positive | FP – False Positive |
| Predicted – Negative | FN – False Negative | TN – True Negative |
Tip: have a good sense when you want to minimize FN or FP.
E.g., for quality assurance use case: if we throw out one product we lose X dollars. However if the customer gets a broken device we have to spend 10 * X dollars to fix it. In this situation we might select a KPI which tries to minimize false negatives (potentially at the expense of increased FP rate).
Common performance KPIs
Recall, sensitivity, true positive rate: TP / (TP + FN) (column-wise in the confusion matrix)
Precision: TP / (TP + FP) (row-wise in the confusion matrix)
Specificity: TN / (TN + FP) (right column-wise in the confusion matrix)
F1-score: 2 * Prec * Rec / (Prec + Rec) = 2 * TP / (2 * TP + FP + FN)
Accuracy: correct / all = (TP + TN) / (TP + TN + FP + FN)
Area Under Curve – AUC: represents the probability of a model being able to correctly classify 1-1 randomly selected positive and negative class. Scale and classification threshold invariant, typically used for (binary) classification.
Tip: learn all KPIs for the exam and expect to calculate them (without calculator) based on a given confusion matrix.
Conclusion
This post was a dense summary of the most typical machine learning algorithms and their evaluation. In the previous posts I have introduced the AWS Machine Learning Speciality certificate for AWS Certified Machine Learning Consultants and AWS Data Engineering services for The AWS Data Engineering Consultants and the Top 7 Explorative Data Analysis Methods. In the next post I will present all AWS AI Services. See you there!
Photo by Alex Knight on Unsplash